Yiping Wang 王宜平
 |
Yiping Wang |
About me
I'm a Ph.D. student (2023.9 - Present) in Paul G. Allen School of Computer Science & Engineering at University of Washington, fortunate to be advised by Prof. Simon Shaolei Du. I am also a Member of Technical Staff at XAI.
From June 2024 to November 2025, I interned at Microsoft, where I was fortunate to be advised by Yelong Shen and Shuohang Wang. Prior to UW, I studied Computer Science and Mathematics at Zhejiang University, where I earned an honors degree from Chu Kochen Honors College.
My long-term research goal is to develop safe and scalable AI systems with super-human capabilities that can drive significant scientific progress. Recently, I'm focusing on reinforcement learning for reasoning in large language models and AI for math. I have also explored diverse topics, including multimodal and machine learning theory.
Key News
11/2025: Release ThetaEvolve. It enables RL training on dynamic environments like AlphaEvolve, and scales test-time learning (pure inference or RL training) for evolution on open optimization problems. We show that an 8B model can achieve better best-known bounds on open problem like Circle Packing under ThetaEvolve.
11/2025: Release RLVE, where we scale RL with adaptive, verifiable environments with auto-tuning difficulty for model capability frontiers.
10/2025: Honored to receive the Amazon AI Ph.D. Fellowship!
05/2025: Release Spurious Rewards, which uses RLVR with random reward to incentivize the reasoning capability of pretrained models.
05/2025: Present One-Shot RLVR in BAAI Talk.
04/2025: Release One-Shot RLVR (Code, X), rank as #1 Paper of the day on HuggingFace Daily Papers! We find that with a strong base model, RLVR can improve LLM reasoning with only one proper training example.
12/2024: Release a new video generation benchmark StoryEval, showing that current top video generative models can not present multi-event stories like "How to Put an Elephant in a Refrigerator".
06/2024: Start my internship at Microsoft!
05/2024: Release CLIPLoss, which designs a simple but efficient data selection methods for CLIP pretraining, gets the new SOTA in DataComp benchmark.
10/2023: Release JoMA, which analyzes the training dynamics of multilayer transformer and characterizes the role of self-attention and MLP nonlinearity.
09/2023: Become a husky in UW!
05/2023: Release Scan&Snap, which analyzes the training dynamics of 1-layer linear transformer with next token prediction loss.
Main Research
(* denotes equal contribution or alphabetic ordering, † denotes corresponding author)
LLM RL
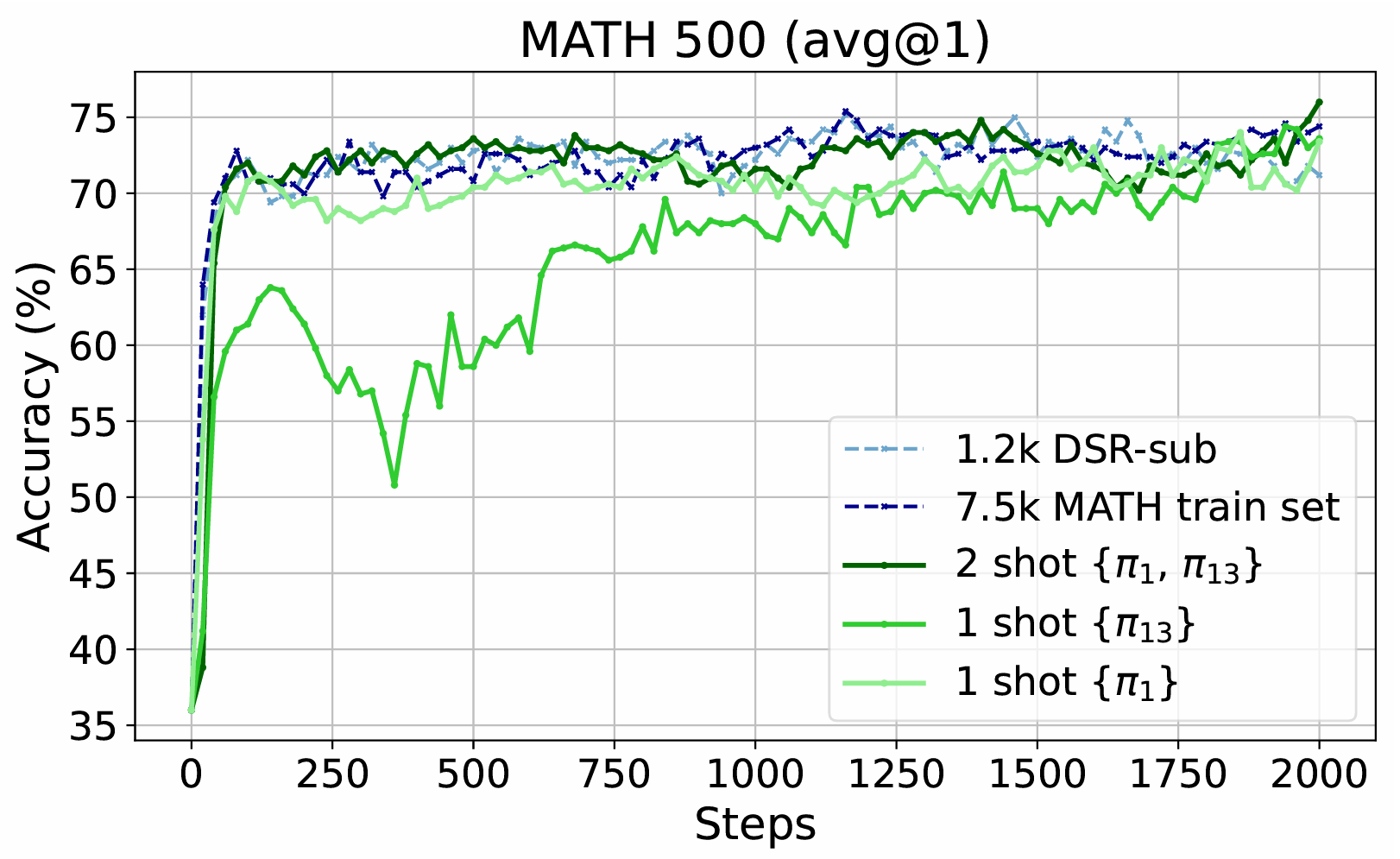 |
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
|
Multimodal
 |
Is Your World Simulator a Good Story Presenter? A Consecutive Events-Based Benchmark for Future Long Video Generation
|
 |
CLIPLoss and Norm-Based Data Selection Methods for Multimodal Contrastive Learning
|
Theory of Transformer Dynamics
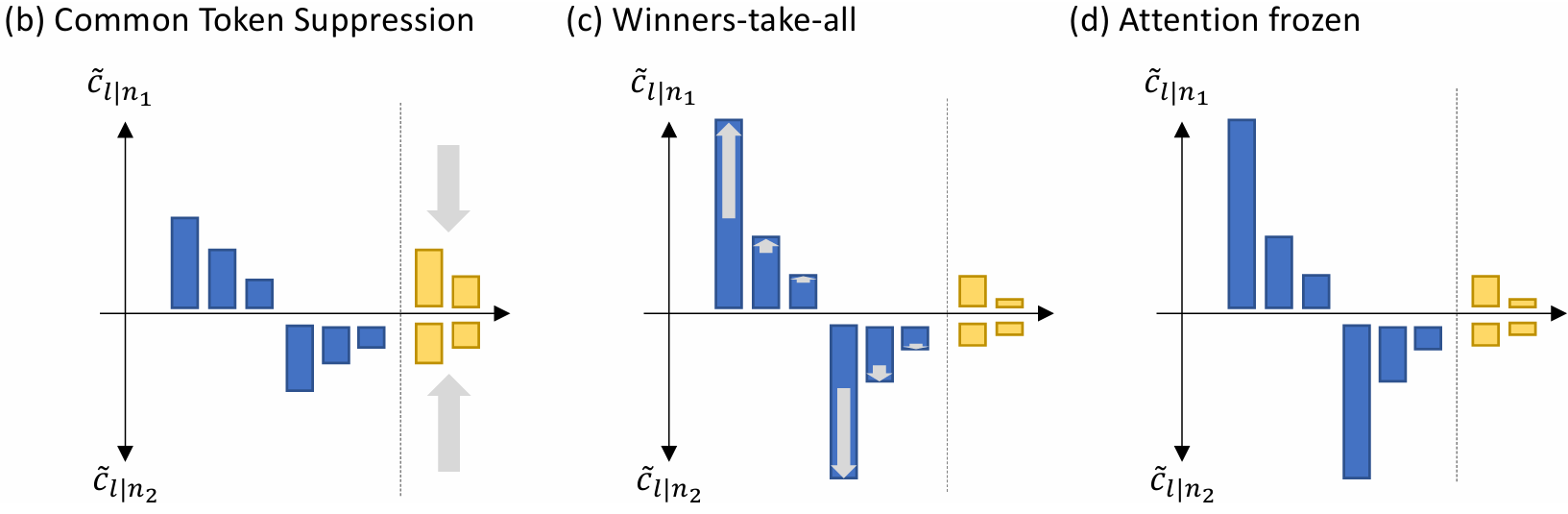 |
Scan and Snap: Understanding Training Dynamics and Token Composition in 1-layer Transformer
|
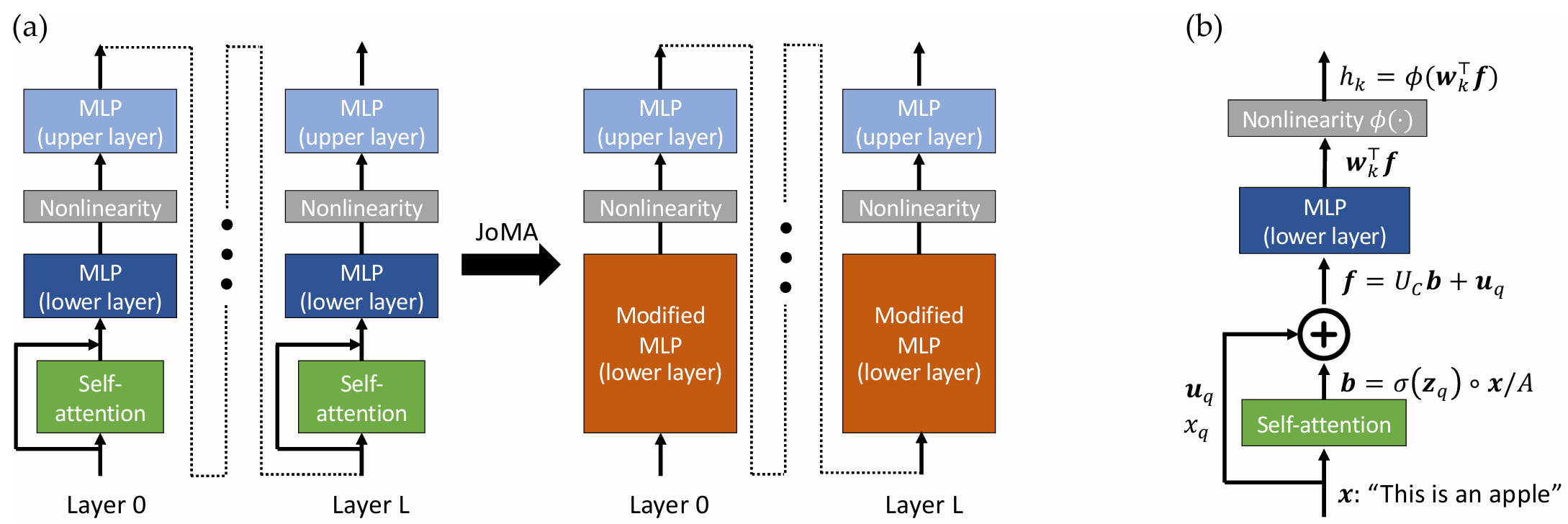 |
JoMA: Demystifying Multilayer Transformers via JOint Dynamics of MLP and Attention
|